

C언어 복습
📖UNIT 3.
C언어를 다시 복습해보자. Hello, World!를 출력하는 내용이다.

C언어는 되게 오랜만이다. 어쨌든 저 코드를 치고 실행해보자. 맥에서 c도 무난히 돌아간다.
한 줄 한 줄 분석해보자.
먼저 stdio.h 헤더파일을 참조하고 있다. 그 이후 main() 함수가 시작하게 되면 printf()함수를 호출하게 된다.
이 때 호출할 때 "Hello, World!\n" 를 인자로 전달한다. 그리고 return 0을 통해 반환값을 반환한다.
이런식으로 프로그램이 실행된다.
만약 파이선 처럼 서식지정자를 사용하고 싶다면
printf("%s\n", "Hello, World!");위와 같이 코드를 작성해주면 된다.
그렇게 되면 %s 자리에는 첫 번째 문자열이 오게 되는데, 그것이 "Hello, World!" 이다.
서식 지정자를 두개 사용해서 그 뒤에도 값을 두 개를 준다면 당연히 두개도 출력될 수 있다.
📖UNIT 4.
기본 문법도 공부해보자.
먼저 c언어는 세미콜론(;)을 붙여야 한다.
그리고 한 줄 주석을 사용할 때는 (#)을, 여러줄을 할 때는 /* */을 사용해야 한다.
// 이건 한 줄 주석
/*
이건 여러 줄 주석.
dpqpqpqppq
*/
C언어에서 중괄호 ( {, } )는 해당 반복문 또는 조건문 등의 영역을 나타낸다.
if (a == 3){
printf("%d", a);
}물론 해당 코드는 한 줄 짜리기에 조건문과 한 줄에 같이 작성할 수도 있다.
그리고 해당 조건문안에 포함되었다는 것을 들여쓰기를 통해서 알려준다. 파이썬에서는 공백 네 칸이다.
하지만 C언어에서는 그 기준이 없기에, 그냥 기존처럼 공백 네 칸으로 진행하자.
📖UNIT 5.
이번엔 변수를 만들어보자.
C언어의 자료형에는 여러개가 있다. int, float, char, double, 등등 여러개가 있다.
그래서 변수를 선언하는 방법으로는 int num; 이런 방식으로 선언해주면 된다.
- 영문 문자와 숫자를 사용할 수 있습니다.
- 대소문자를 구분합니다.
- 문자부터 시작해야 하며 숫자부터 시작하면 안 됩니다.
- _ (밑줄 문자)로 시작할 수 있습니다.
- C 언어의 키워드(int, short, long, float, void, if, for, while, switch 등)는 사용할 수 없습니다.
위는 c언어에서 변수를 선언할 때 주의해야 하는 점들이다.
이번엔 c언어의 자료형들에 대해 알아보자.
- char, short, int, long: 정수(저장할 수 있는 크기가 다릅니다)
- float, double: 실수
- void: 형태가 없는 자료형(포인터를 사용할 때, 함수의 반환값을 표현할 때 등 다양하게 사용됩니다)
이렇게 되어있다. 두 내용 모두 코딩도장에서 복사해왔다.
변수 이름 규칙은 파이썬과 똑같다. 물론 파이썬의 키워드와 C의 키워드는 다르겠지만...
int num1 = 10;
int num2;
num2 = 20;c언어에서는 두가지 방법으로 변수를 선언할 수 있다.
첫 번째 방법은 선언과 초기화를 동시에 진행해준 것이다.
두 번째 방법은 선언을 해주고 초기화를 진행해주는 방식이다.
이걸 어떻게 출력하면 될까. 바로 서식지정자를 이용하면 된다.
int a = 10;
printf("%d", a)파이썬과 매우 유사한 구조를 띄고 있다.
📖UNIT 6.
브레이크 포인트는 F9를 통해 걸어주도록 하자.
📖UNIT 7.
정수 자료형에 대해 좀 더 알아보도록 하자.
먼저 c언어에는 unsigend와 signed가 있다. signed란 말 그대로 부호가 있다는 소리이다.
부호가 없는 자료형이 unsigend이다. unsigend의 경우 양수만 표현이 되기에 수의 범위크기는 똑같지만 그 범위가 0부터
시작하게 된다.
자료형크기범위비고
| char signed char |
1바이트, 8비트 | -128~127 | |
| unsigned char | 1바이트, 8비트 | 0~255 | |
| short short int |
2바이트, 16비트 | -32,768~32,767 | int 생략 가능 |
| unsigned short unsigned short int |
2바이트, 16비트 | 0~65,535 | int 생략 가능 |
| int signed int |
4바이트, 32비트 | -2,147,483,648~ 2,147,483,647 | |
| unsigned unsigned int |
4바이트, 32비트 | 0~4,294,967,295 | int 생략 가능 |
| long long int signed long signed long int |
4바이트, 32비트 | -2,147,483,648~ 2,147,483,647 | int 생략 가능 |
| unsigned long unsigned long int |
4바이트, 32비트 | 0~4,294,967,295 | int 생략 가능 |
| long long long long int signed long long signed long long int |
8바이트, 64비트 | -9,223,372,036,854,775,808~ 9,223,372,036,854,775,807 |
int 생략 가능 |
| unsigned long long unsigned long long int |
8바이트, 64비트 | 0~18,446,744,073,709,551,615 | int 생략 가능 |
이 표를 참고하도록 하자. char는 분명 문자를 담는 변수라고 생각할 수 있다. 하지만 char의 경우에도 사실 아스키코드 값이 들어가는 것이기에 정수형 변수를 사용한다. 외울 필요는 없다. 필요할 때 마다 참고해서 보도록 하자.

근데 위에서 long은 Windows 기준으로 작성되었다. (Windows는 왜 int와 long int의 크기를 똑같이 계산하는 걸까.)
| 운영체제 | CPU(플랫폼) | 바이트 크기 | 비트 크기 |
|---|---|---|---|
| Windows | x86(32비트) | 4 | 32 |
| x86-64(64비트) | 4 | 32 | |
| 리눅스 | x86(32비트) | 4 | 32 |
| x86-64(64비트) | 8 | 64 | |
| OS X | x86(32비트) | 4 | 32 |
| x86-64(64비트) | 8 | 64 |
이 표를 참고해서 각 운영체제의 long크기를 참고하자.
| 데이터 모델 | short | int | long | long long | 포인터 | CPU 및 운영체제 |
|---|---|---|---|---|---|---|
| IP16L32(near) | 16 | 16 | 32 | 16 | x86(16비트): MS-DOS | |
| I16LP32(far) | 16 | 16 | 32 | 32 | x86(16비트): MS-DOS | |
| ILP32 | 16 | 32 | 32 | 64 | 32 | x86(32비트): 유닉스 및 리눅스, 솔라리스, BSD, OS X, Windows |
| LLP64/IL32P64 | 16 | 32 | 32 | 64 | 64 | x86-64(64비트): Windows |
| LP64/I32LP64 | 16 | 32 | 64 | 64 | 64 | x86-64(64비트): 유닉스 및 리눅스, 솔라리스, BSD, OS X |
| ILP64 | 16 | 64 | 64 | 64 | 64 | |
| SILP64 | 64 | 64 | 64 | 64 | 64 |
그럼 이제 정수형 변수를 선언하여 보자.
두 번째 표를 참고해서 코딩을 해보자.
#include <stdio.h>
int main(){
char num1 = -10; //1byte, minus
short num2 = 30000; //2byte
int num3 = -1234567890; // 4yte, minus
int num4 = 1234567890; //4byte
long num5 = 1234567890123456789; //Windows : 4byte, Mac : 8byte
long long num6 = 1234567890123456789; //Windows : 8byte, Mac : 8byte
long long num7 = -1234567890123456789; //Windows : 8byte, Mac : 8byte , minus
printf("%d %d %d %ld %lld %lld\n", num1, num2, num3, num4, num5, num6, num7);
return 0;
}이 코드를 실행하면 어떻게 될까.

출력이 스무스하게 되는 것을 확인할 수 있다.
%d는 char, short, int 의 범위에서 사용된다.
%ld는 long int에서 사용된다.
그럼 long long int는 당연히 %lld 겠지 ㅎㅎ
부호를 없앤다면, 그래도 자료형의 범위는 똑같지만 그 범위가 0부터 시작되어 결국 해당 자료형의 최댓 값은 두배가 된다.
그때는 %d 대신 %u를 사용하면 된다. 그리고 %lu와 %llu 순으로 써주면 된다.
이번엔 오버플로우(Over Flow)에 대해 알아보자.
#include <stdio.h>
int main(){
char num1 = 128;
printf("%d\n", num1);
}
분명 128을 char에 넣었는데, -128이 나왔다. 이런 것을 오버플로우라고 한다. 그럼 오버플로우는 왜 발생할까 ?
먼저 char의 범위를 생각해보자. 바로 -128 ~ 127이다. 근데 num1에 128을 넣었다. 이미 char의 범위를 벗어나게 되었다.
결국 오버플로우가 발생한 것이다. 역으로 -128에서 -1을 해주면 127이 나오게 된다. 이는 언더플로우라고 한다.
이번엔 자료형의 크기를 구해보자.
#include <stdio.h>
int main(){
printf("");
printf("%d\n", sizeof(char));
printf("%d\n", sizeof(short));
printf("%d\n", sizeof(int));
printf("%d\n", sizeof(long int));
printf("%d\n", sizeof(long long int));
return 0;
}sizeof(표현식), sizeof(자료형) 이런 방법을 통해 사이즈를 구할 수 있다.

이런 방법을 통해 자료형의 크기를 구할 수 있다. 물론 단위는 byte일 것이다.
근데 되게 애매하다고 느낄 것이다. 운영체제에 따라, 그리고 컴퓨터가 16비트냐 32비트냐 64비트냐에 따라 자료형이 다르기
때문이다.
그러니 통용된 자료형을 사용하는게 좋을 것 같다.
stdint.h라는 헤더파일이 있다. 이것을 사용하도록 하자.
#include <stdio.h>
#include <stdint.h> // 크기별로 정수 자료형이 정의된 헤더 파일
int main()
{
int8_t num1 = -128; // 8비트(1바이트) 크기의 부호 있는 정수형 변수 선언
int16_t num2 = 32767; // 16비트(2바이트) 크기의 부호 있는 정수형 변수 선언
int32_t num3 = 2147483647; // 32비트(4바이트) 크기의 부호 있는 정수형 변수 선언
int64_t num4 = 9223372036854775807; // 64비트(8바이트) 크기의 부호 있는 정수형 변수 선언
// int8_t, int16_t, int32_t는 %d로 출력하고 int64_t는 %lld로 출력
printf("%d %d %d %lld\n", num1, num2, num3, num4); // -128 32767 2147483647 9223372036854775807
uint8_t num5 = 255; // 8비트(1바이트) 크기의 부호 없는 정수형 변수 선언
uint16_t num6 = 65535; // 16비트(2바이트) 크기의 부호 없는 정수형 변수 선언
uint32_t num7 = 4294967295; // 32비트(4바이트) 크기의 부호 없는 정수형 변수 선언
uint64_t num8 = 18446744073709551615; // 64비트(8바이트) 크기의 부호 없는 정수형 변수 선언
// uint8_t, uint16_t, uint32_t는 %u로 출력하고 uint64_t는 %llu로 출력
printf("%u %u %u %llu\n", num5, num6, num7, num8); // 255 65535 4294967295 18446744073709551615
return 0;
}
그러면 각 자료형의 최대 최솟값은 어떻게 알 수 있을까 ?
물론 구글링을 통해서 알아낼 수도 있겠지만, stdint.h에는 그 최대와 최솟값이 정해져 있다. (상수로)
- 부호 있는 정수(signed) 최솟값: INT8_MIN, INT16_MIN, INT32_MIN, INT64_MIN
- 부호 있는 정수 최댓값: INT8_MAX, INT16_MAX, INT32_MAX, INT64_MAX
- 부호 없는 정수(unsigned) 최솟값: 0
- 부호 없는 정수 최댓값: UINT8_MAX, UINT16_MAX, UINT32_MAX, UINT64_MAX
이렇게 정해져있다.
📖UNIT 8.
이번엔 실수형을 선언해보자.
실수형은 정수형과 동일하므로 차이점만 알아보자.
| 자료형 | 크기 | 범위 | 유효자릿수 | 비고 |
| float | 4바이트, 32비트 |
1.175494e-38~3.402823e+38 | 7 | IEEE 754 단정밀도 부동소수점 |
| double | 8바이트, 64비트 |
2.225074e-308~1.797693e+308 | 16 | IEEE 754 배정밀도 부동소수점 |
| long double |
8바이트, 64비트 |
2.225074e-308~1.797693e+308 | 16 | IEEE 754 배정밀도 부동소수점 |
윽. 숫자에 왜 e가 들어가는 것일까.
미적분에서 배운 자연상수가 떠올랐다. 물론 그것일 리는 없다.
이런 것을 지수표기법이라고 한단다.
아래 내용을 참고하도록 하자.
- 실수e+지수: 실수 * 10의 거듭제곱입니다. 2.1e+3이라면 2.1 * 1000 = 2100이 됩니다.
- 실수e-지수: 실수 * (1 / 10의 거듭제곱)입니다. 2.1e-2라면 2.1 * (1/100) = 0.021이 됩니다.
그렇다면 long double은 운영체제마다 모두 똑같을까 ?
| 운영체제 | CPU(플랫폼) | 바이트 크기 | 비트 크기 |
|---|---|---|---|
| Windows | x86(32비트) | 8 | 64 |
| x86-64(64비트) | 8 | 64 | |
| 리눅스 | x86(32비트) | 12 | 96 |
| x86-64(64비트) | 16 | 128 | |
| OS X | x86(32비트) | 16 | 128 |
| x86-64(64비트) | 16 | 128 |
정말 복잡하구마잉... 리눅스랑 윈도우는 64비트 기준으로는 같다.
이번엔 부동소수점 규약에 대해 알아보자. 이 부분은 자세하게 알 필요는 없고 읽어보는 정도이면 괜찮다.
먼저 컴퓨터에서는 값을 0과 1로 저장한다. 이러면 소수는 어떻게 저장해야 할까
부동 소수점 방법은 자료형의 일정 부분을 비트로 나눈다.
그리고 이후 부호 가수 기수 지수를 저장하여 실수를 표현한다.
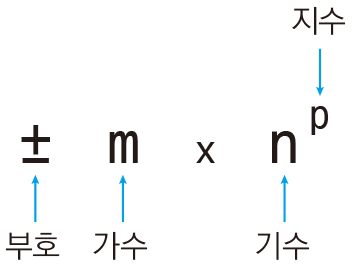
이 이미지를 참고해보자. 컴퓨터는 값을 저장할 때 2진수로 저장하게 되므로 기수는 2로 정해져있다.
물론 2 자체를 메모리에 따로 저장 시키지는 않는다.
이제 자료형을 이용하여 저장해보자.
자료형에는 float, double, long double이 존재한다.
#include <stdio.h>
int main(){
float num1 = 0.1f;
double num2 = 3867.215820;
long double num3 = 9.327513l;
printf("%f %f %Lf\n", num1, num2, num3); // 0.100000 3867.215820 9.327513
return 0;
}
이렇게 코드를 작성해보자.

출력이 제대로 되는 것을 확인할 수 있다.
먼저 float으로 자료를 선언할 경우 값 뒤에 'f'를 붙여줘야 한다.
또 long double의 경우 값 뒤에 'l'을 붙여줘야 한다.
이런 값들을 지수출력 하고 싶다면 %f 대신 %e를 사용하면 된다.
📖UNIT 9.
c언어에서는 정수형 자료 char를 이용하여 문자 하나를 저장한다. 결국 문자도 정수인 것이다.

이 아스키코드는 절대 외우는 것이 아니다. 필요할 때 마다 참고해서 읽어보자.
char의 범위와 똑같이 127까지만 존재한다. (물론 char의 경우 minus도 존재하겠지만. ..)
char c1 = 'h';
char c2 = 'hh';문자열 한 개만 묶을 때는 작은 따옴표를 사용하고, 문자열을 묶을 때는 큰 따옴표를 사용한다.
그렇기에 c2는 잘못된 표현법이다.
#include <stdio.h>
int main(){
char c1 = 'a';
char c2 = 'b';
printf("%c %d \n", c1, c1);
printf("%c %d \n", c2, c2);
return 0;
}이런 코드를 작성해보자.

%c를 통해 문자로 출력도 가능하고, %d를 통해 해당 문자의 아스키 값도 확인할 수 있다.
또 ASCII CODE 규칙에 의해 정수로 저장되므로 덧셈 뺄셈도 가능하다.
printf("%d %c", 'a' + 1, 'a' + 1);이런식으로 말이다.
| 10 | 0x0A | LF | \n | 개행, 라인 피드(Line Feed), 새 줄(new line), 줄바꿈 |
| 13 | 0x0D | CR | \r | 복귀, 캐리지 리턴(Carriage Return), 줄의 끝에서 시작 위치로 되돌아감 |
| 9 | 0x09 | TAB | \t | 수평 탭(horizontal tab) |
그리고 이건 c언어에서 제어문자 이니까 좀 알아두자.
📖UNIT 10.
이젠 상수 사용법을 알아보자.
const int cons1 = 10;상수는 이와 같이 선언해준다.
이때 cons1을 상수, 10을 리터럴이라고 해준다.
const는 자료형 뒤에 붙여줘도 된다.
만약 const로 선언된 상수를 변수처럼 값을 바꾸고자 시도하게 된다면 오류가 뜨게 된다.
리터럴은 상수에만 사용되는 개념은 아니다.

이것은 정수 리터럴을 사용할 때 크기와, 자료형을 명확히 하기 위해 사용하는 접미사이다.

이것은 실수에서 사용되는 리터럴 접미사이다.
📖UNIT 11.
이젠 값 입력을 받아보자. 당연히 scanf() 함수를 사용하면 된다. (보안 상의 문제가 있긴 하지만 ...)
#include <stdio.h>
int main(){
int num;
printf("Input the Inteager : ");
scanf("%d", &num);
printf("%d\n", num);
return 0;
}이 코드를 작성해보자.

스무스하게 실행된다.
실수는 입력될 때
float : %f
double : %lf
long double : %Lf
로 서식지정자를 정해줘야 한다.
문자의 경우에는 %c를 사용해줘야 한다.
getchar() 함수의 경우 값을 입력받고, 그 가장 앞의 글자를 반환한다.
char a = getchar()그래서 이런 코드가 존재할 수 있다. 파이썬과 유사하다.
📖UNIT 12.
c에서는 값을 더하거나 뺄 수도 있다.
int a = 3;
printf("%d", a+5);이런 코드 당연히 가능하다.
만약에 a에 5를 더한 값을 a에 저장하고 싶다면
int a = 3;
a = a + 5;
a += 5;윗 줄과 아랫 줄 두 가지 방법으로 진행할 수 있다.
빼는 것은 당연히 a -= 5; 와 같이 진행 될 것이다.
📖UNIT 13.
이번에는 전위 연산과 후위 연산에 대해 알아보자.
int a = 5;
int b = 5;
printf("%d", ++a);
printf("%d", b++);이런 코드를 작성하게 된다면 실행 결과는 6과 5가 나오게 된다.
물론 프로그램이 종료될 시점에서는 a와 b는 모두 6일 것이다.
전위 연산의 경우 먼저 연산을 진행해주고, 해당 연산이 진행된 코드를 실행하게 된다.
하지만 후위 연산의 경우 코드를 먼저 실행한 이후 연산이 진행된다. 이런 점을 유념해서 코드 작성을 할 필요가 있다.
char 또는 실수 자료형 모두 이런 방법으로 1씩 증감이 가능하다.
📖UNIT 14.
이번엔 곱셈과 나눗셈을 진행해보자.
printf("%d %d", 7 * 2, 7 / 2);이런 코드를 작성하게 된다면 14와 3이 출력된다.
printf("%f\n", 2.73f * 3.81f);이 코드도 실행해보자.

실제 계산값은 10.4013인데 10.401299가 출력된다. 즉 오차가 존재한다. (오차가 꽤 큰데 ? )
📖UNIT 15.
이번엔 나머지 연산을 진행해보자.
나머지 연산은 %이다.
printf("%d", 7 % 2);이런 코드를 작성하게 된다면 1이 출력된다.
나머지 연산은 정수에서만 진행 가능하다.
- fmod(나누어지는수, 나누는수);
- double fmod(double _X, double _Y);
- fmodf(나누어지는수, 나누는수);
- float fmodf(float _X, float _Y);
- fmodl(나누어지는수, 나누는수);
- long double fmodl(long double _X, long double _Y);
실수의 경우 fmod, fmodf, fmodl 와 같은 함수들이 있다. 이런 함수를 이용하여 나머지를 구할 수 있다.
math.h 헤더파일에 존재한다.
'스터디 그룹 > ProjectH4C' 카테고리의 다른 글
| ProjectH4C 2개월 1주차 과제 C & Python (2) | 2021.02.20 |
|---|---|
| ProjectH4C 2개월 1주차 과제 (UNIT16 ~ UNIT33) (0) | 2021.02.20 |
| ProjectH4C 1개월 3,4주 과제 생활코딩 - HTML (2) (0) | 2021.02.13 |
| ProjectH4C 1개월 3,4주 과제 생활코딩 - HTML (1) (0) | 2021.02.09 |
| ProjectH4C 1개월 3,4주 과제 (코드업 66~100) (0) | 2021.02.07 |